Kinematic Motion Diffusion: Towards Semantic-adaptive Motion Synthesis via Kinematic Guidance
Accepted by ICMSSP 2024


Authors: Leizhi Li, Jincheng Yang, Yichao Zhong, Junxian Guo
This project uses HumanML3D
Abstract
3D human motion synthesis is a crucial task with broad applications across various industries. Although recent advancements in data-driven models like GANs, VAEs, and denoising diffusion models have improved the quality and diversity of generated motions, the integration of natural language as a descriptor for motion synthesis presents unique challenges. Current methods often fail to ensure coherence between text semantics and the resulting motion sequences, a gap that is particularly evident in applications requiring subtle semantic interpretation. In this paper, we introduce Kinematic Motion Diffusion (KMD), a novel model that leverages kinematic phrases (KP) as an intermediate representation to bridge the domain gap between language and motion. By establishing multiple classifiers based on KPs, KMD utilizes a high level of motion abstraction grounded in human knowledge to generate more semantically coherent motions. We propose a semantic adaptive activation method that dynamically adjusts classifier compounds, enabling the model to accommodate diverse motion generation scenarios. KMD achieves a considerable performance in many metrics on HumanML3D with a much simpler architecture compared with other state-of-the-art works.
Architecture
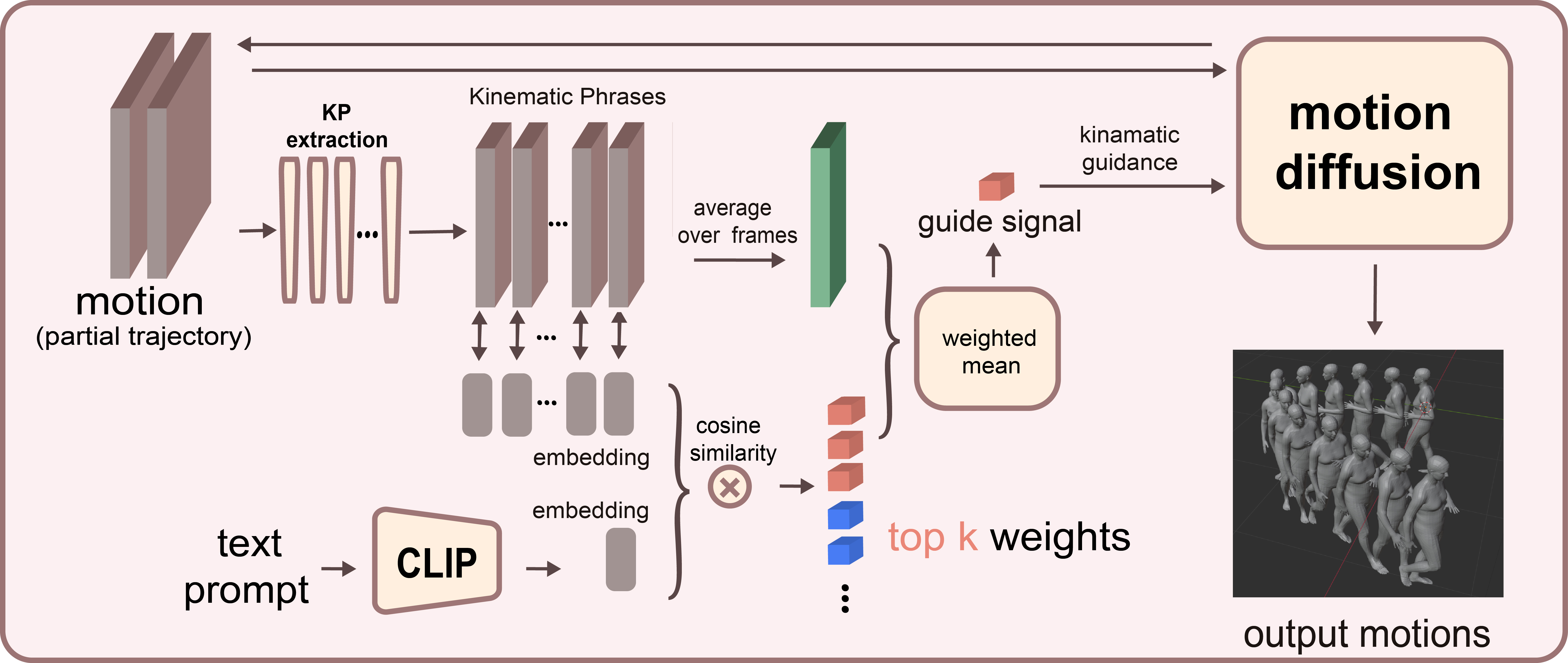
This work aims to generate human motion based on a natural language description. Our framework consists of a KP-guided motion diffusion model and a set of learnable kinematic classifiers. We adopt a one-stage pipeline to generate motion as shown in Figure, i.e., we directly generate motion sequences without first generating the corresponding trajectory, nor do we use any keyframes in our pipeline. KMD contains a frozen CLIP text encoder $\mathcal{E}$ of dimension $D$. The kinematic classifiers consists of $m$ KP extract functions $\mathbf{F}=[f_1.f_2,\dots,f_m]$ and individual phrase is assigned with a semantic embedding $\mathbf{E}=[e_1,e_2,\dots,e_m]$ of the same dimension as $T$.
With each incoming text description of desired motion that is first decoded by CLIP into text token $t$, KMD calculates the affinity with kinematic classifier embeddings:
\[\begin{equation} \textbf{A}=[\frac{t\cdot e_i}{|t|\cdot|e_i|}]_{i=1}^m \end{equation}\]KMD uses the affinity scores to filter the kinematic classifiers and as the weight to assemble individual KP classifiers for diffusion sampling. Because guidance only functions in the sampling procedure of the diffusion model without intervening in the reverse process network, we adopt a pre-trained motion diffusion model provided by Guided Motion Diffusion.
Evaluation
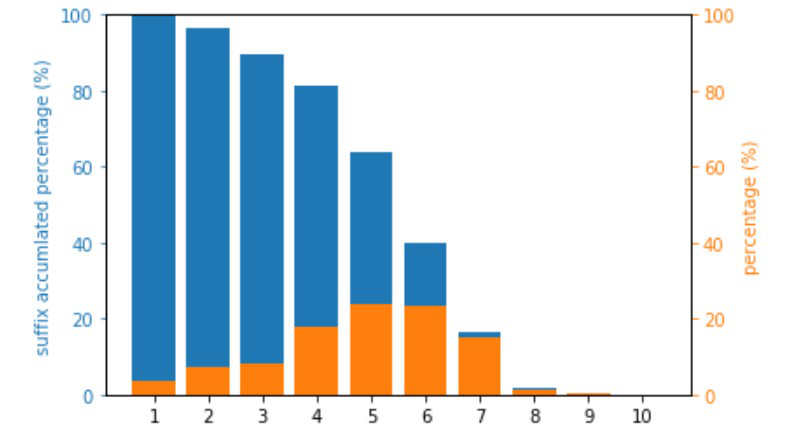
Ablation study on top-$k$ strategies
In this ablation study, we evaluate the performance of our method for $k=10,50,100,200$ and $k=\infty$ (i.e., no KP indicator is ignored when calculating $G$). $\textbf{Bold}$ face indices the best result, while $\underline{underscore}$ refers to the second best one.
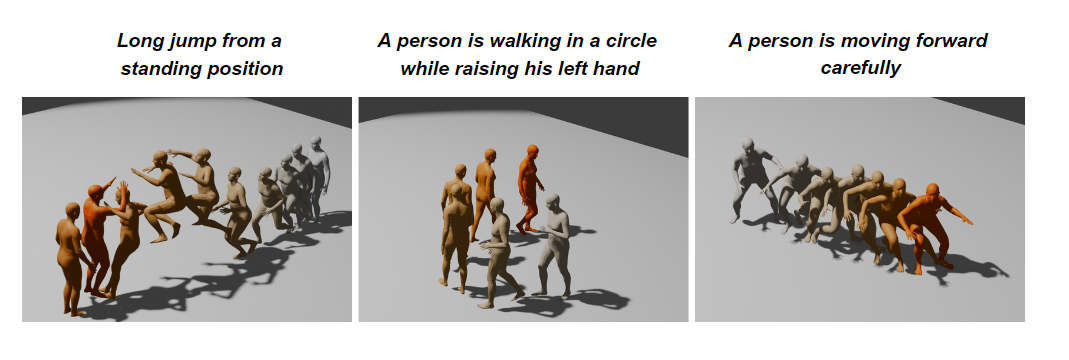
Comparison examples

Comparison examples with GMD on some generations.
KMD’s two columns refer to two experiments with different seeds. The brighter the colors, the later in time.
Credit
SJTU Course CS348: Computer Vision (2023 Fall) Team D Project.
This page is maintained by CS348 - Group D.
CLIP: openai/CLIP
Guided Motion Diffusion: korrawe/guided-motion-diffusion
Kinematic Phrases: Bridging the Gap between Human Motion and Action Semantics via Kinematic Phrases
HumanML3D: EricGuo5513/HumanML3D